Upload files from Amazon s3
From the connect page, click on add new connection button ("+" button) to add a new datasource.
Scroll to the "File" section and click on "Amazon S3" in the list of datasources

Provide required details listed below to upload:
- Dataset name: Name for the data source connection you want to give
- Dataset Tags: Tags you wish to associate with respective datasource
- AWS Access Key ID: Provide AWS access key ID that will be used to connect to your running Redshift instance
- AWS Access Key Secret: Provide AWS access key secret that will be used to connect to your running Redshift instance
- File Location: Browse and Upload the file that you would want to import using the File Location option. It will open a S3 file browser for you to select the file that you want to import from S3. You can select a particular file from the menu or select a folder to import all containing files in the folder.
- File Type: Select the type of the file which you want to import from S3. It may be delimited, log or JSON.
- Quote Character: Specify a quote character which will be used to skip separate within fields
- First Row is Header: Select this check box if the first row is header in your file.
- Separator: Select the type of separator from the drop down. You can select comma (,), tab from the drop down. For other separators, select others from the dropdown and specify your custom one character separator in the Other Separator field.
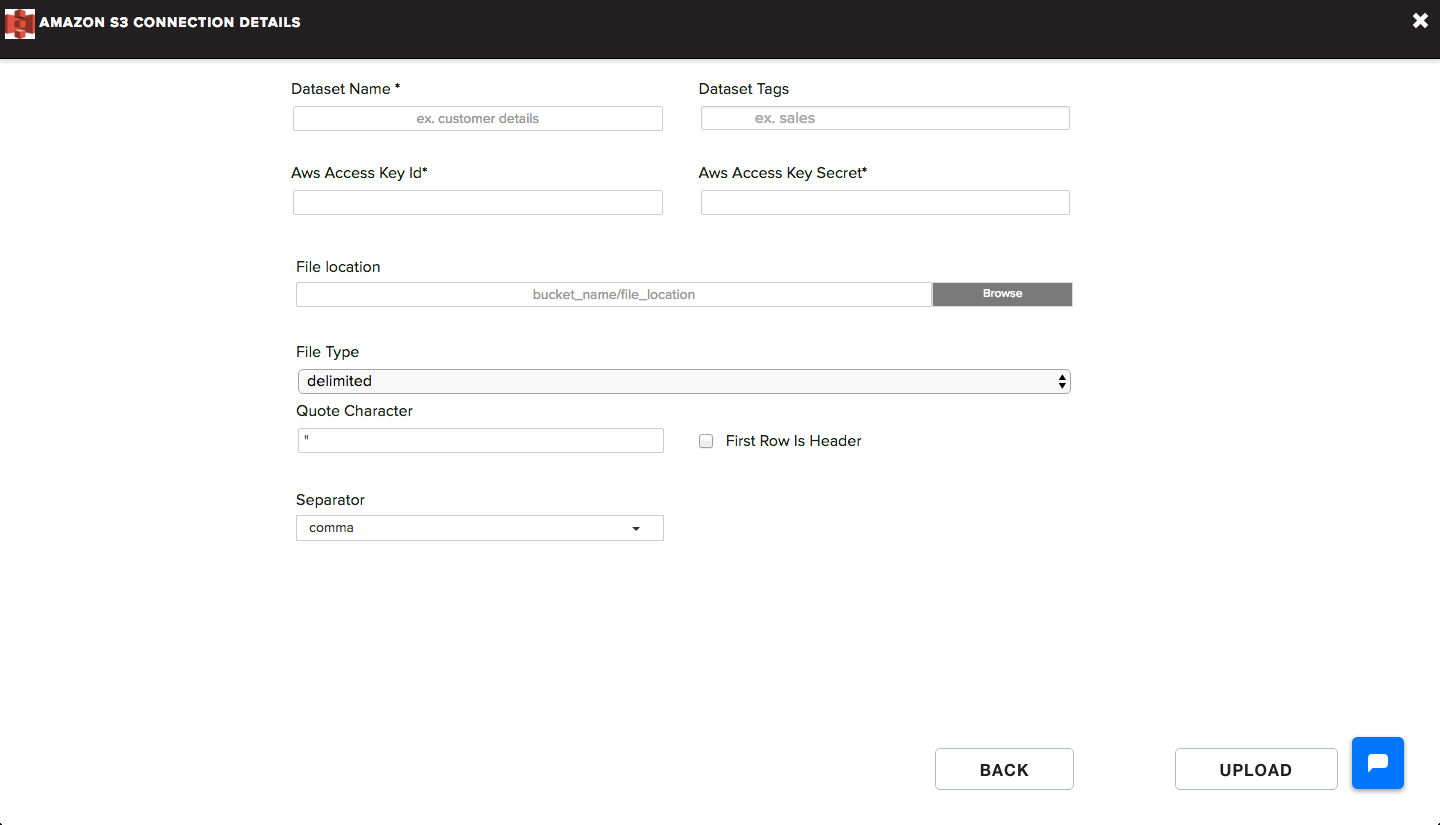 Once you click on Upload, the application will upload file to the server. After the file is uploaded, application will extract a sample data from the file that you have uploaded and take you to the data preparation interface.
Once you click on Upload, the application will upload file to the server. After the file is uploaded, application will extract a sample data from the file that you have uploaded and take you to the data preparation interface.